
When a server goes down, a node runs out of memory, or a network issue starts affecting users, the last thing you want is to find out from a support ticket. But if you have enabled Infrastructure monitoring tools, it would be easy for you to gain visibility into what is actually happening across your servers, networks, containers, and cloud resources.
These system monitoring tools help monitor IT infrastructure, provide insights into infrastructure health, and ensure small issues don’t turn into bigger ones.
The tools below cover the full range: from commercial all-in-one platforms to open-source options you run yourself. They support end-to-end IT monitoring and help teams achieve complete visibility across modern, distributed environments.
Want to understand the core of infrastructure monitoring before choosing a tool? Read our full guide on what is infrastructure monitoring and why it matters.
Quick Comparison: Best Infrastructure Monitoring Tools
| Tool | Best For | Pricing |
| Middleware | Unified infra monitoring at a fraction of competitor costs | Free up to 100 GB/mo; $0.30/GB after |
| Datadog | Cloud-native infra monitoring across large, distributed stacks | From $15/host/mo (Infrastructure Pro) |
| Prometheus | Open-source metrics collection for Kubernetes environments | Free (self-hosted) |
| Dynatrace | Auto-discovery and monitoring across hybrid enterprise infra | From $0.04/host/hr (~$29/mo) |
| Zabbix | Full open-source monitoring for on-prem and hybrid environments | Free (self-hosted); Cloud from $50/mo |
| Nagios | Legacy IT and network infrastructure monitoring | Free (Core); from $2,495 (XI) |
| Uptrace | OpenTelemetry-native tracing and metrics for distributed systems | Free (self-hosted); from $30/mo |
| AppDynamics | Enterprise infra and application performance correlation | From $6/vCPU/mo |
| PRTG | Sensor-based monitoring for on-prem networks and servers | Free up to 100 sensors; from $2,149/yr |
| Site24x7 | All-in-one infra monitoring for mid-market IT teams | From $9/mo (Starter) |
Why Do You Need Infrastructure Monitoring Tools?
Without monitoring in place, your team has no way to know a server is running low on memory or a network link is degrading until something actually breaks. Infrastructure monitoring tools enable end-to-end monitoring of IT environments by keeping a continuous eye on your servers, networks, and containers so your team can catch and fix problems before they affect users.
10 Best Infrastructure Monitoring Tools
We’ve compiled a list of top infrastructure monitoring tools to help you pick the right solution for your team.
1. Middleware
Middleware is a full-stack infrastructure monitoring platform that gives you real-time visibility into your entire infrastructure, including servers, VMs, containers, cloud services, and Kubernetes clusters, through a single dashboard. You can see CPU usage, memory, disk, and network metrics across all your hosts at once, and drill into any resource to understand what is happening at a given point in time.
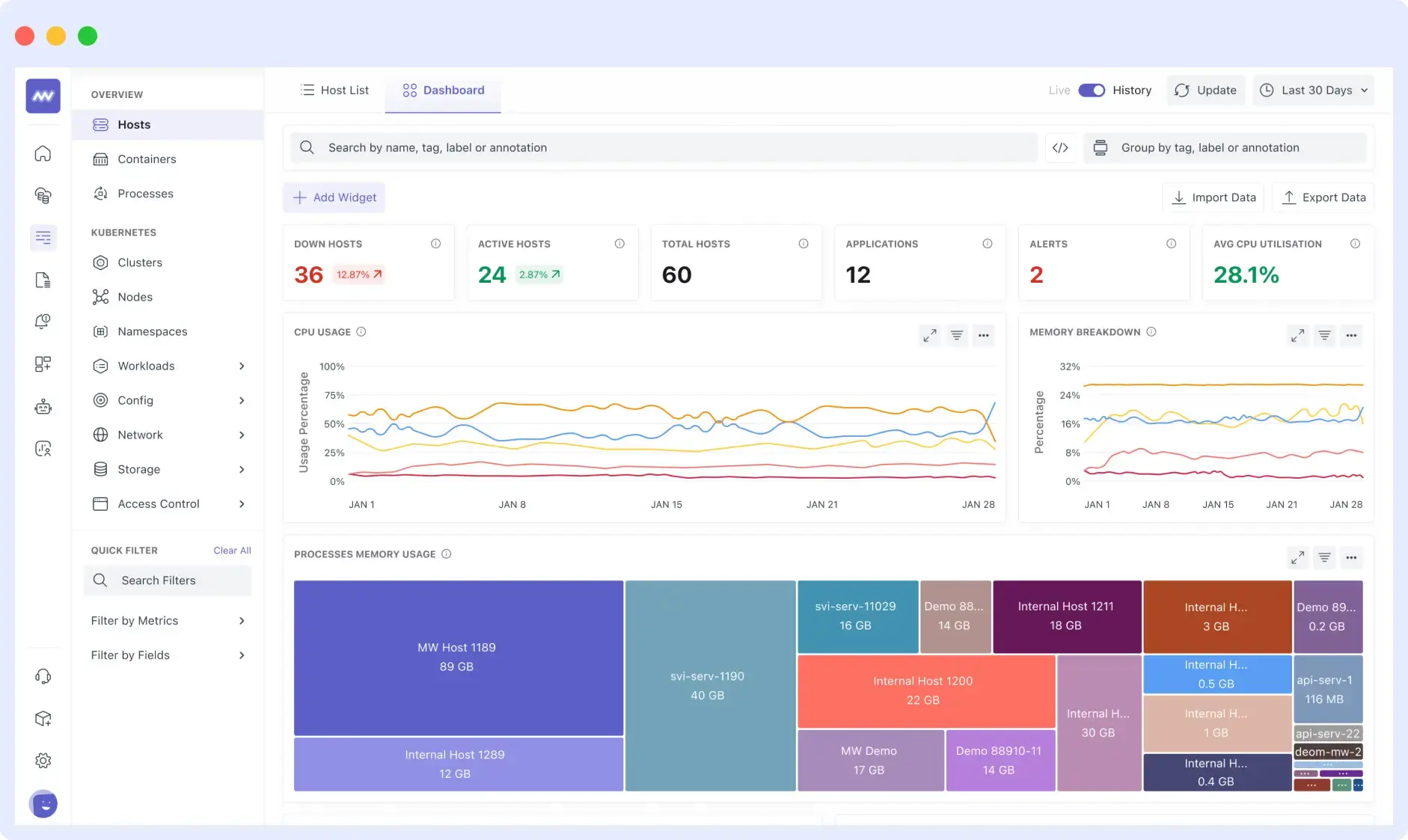
It comes with ready-made dashboards for common infrastructure setups, and alerting is threshold-based, so you can set it up without writing complex queries. For teams watching spend, Middleware lets you turn off individual metrics using tags, so you collect and pay only for what you actually use.
Middleware is a strong fit for DevOps and SRE teams working with cloud-native infrastructure, especially Kubernetes, containers, and microservices based applications. It works well for teams looking to replace multiple monitoring tools with a single platform for logs, metrics, and traces, while keeping observability costs predictable. Teams that need faster troubleshooting will also benefit from OpsAI, which helps identify root causes and suggests fixes using telemetry data.
Pros:
- Real-time visibility into servers, VMs, containers, and Kubernetes clusters
- Works across on-prem, cloud, hybrid, and Kubernetes setups
- Ready-made dashboards for hosts, nodes, and pods out of the box
- Lightweight agent that installs quickly
- Control over what infrastructure metrics get collected, which keeps costs down
Cons:
- A relatively newer platform that is rapidly expanding its capabilities while already seeing strong enterprise adoption.
- Smaller community compared to open-source tools
Pricing:
- Free Forever: Up to 100GB data, 1,000 RUM sessions, and 20,000 synthetic checks per month.
- Pay As You Go: $0.30 per GB for metrics, logs, and traces; $1 per 1,000 RUM sessions; $1 per 5,000 synthetic checks.
- Enterprise: Custom pricing with volume discounts, extended data retention, and dedicated support. See Middleware Pricing in detail.
2. DataDog
Datadog is one of the most widely used observability and system monitoring tools for cloud-native and distributed environments. It monitors hosts, containers, serverless functions, cloud services, and Kubernetes clusters, giving you a clear view of CPU, memory, disk, and network health across all of them. Its 850+ integrations mean it works with almost any existing stack without much setup. Dashboards are well designed, alerting is flexible, and it holds up well at a large scale.
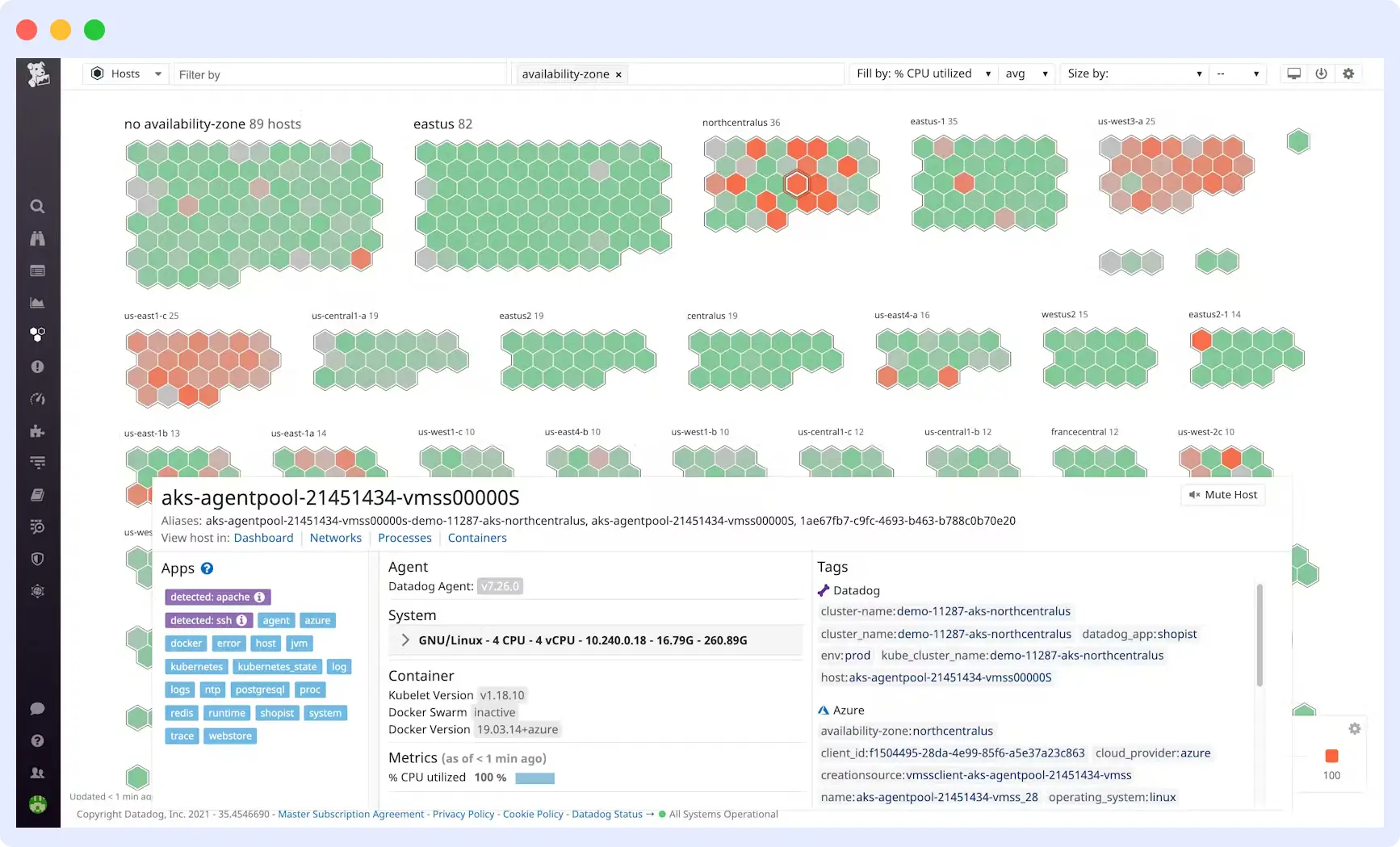
The downside is datadog cost. Datadog charges per host, and as your infrastructure grows, especially when you are running a lot of containers or Kubernetes nodes, the bill goes up fast. Features like log management and APM are billed separately on top of infrastructure monitoring, making it hard to predict monthly costs as usage changes.
👉 Before you commit to Datadog, compare it side-by-side with Middleware.
Read: Middleware vs Datadog – Features, Performance & Pricing.
Pros:
- 850+ built-in integrations with cloud and infrastructure tooling
- Real-time host, container, and Kubernetes monitoring
- Strong support for AWS, Azure, and GCP native services
- Dashboards and alerts are highly customizable
- Automatic anomaly detection on infrastructure metrics
Cons:
- Per-host pricing gets expensive quickly as your infrastructure grows
- Hard to predict costs as infrastructure, logs, and APM are billed separately
- Takes time to learn, especially for new users
Pricing:
- Free tier: Up to 5 hosts, 1-day metric retention
- Infrastructure Pro: $15/host/mo (billed annually)
- Infrastructure Enterprise: $23/host/mo (billed annually)
💰 “Concerned about Datadog’s costs?”
See our breakdown: Datadog Pricing – Is It Worth It in 2026?
3. Prometheus
Prometheus is the standard open-source system monitoring tool for collecting and storing infrastructure metrics. It pulls metrics from your hosts, servers, and containers at set intervals, stores them as time-series data, and lets you query and set alerts using PromQL. Most tools in the Kubernetes world already export Prometheus-compatible metrics, so it slots in without much extra work.
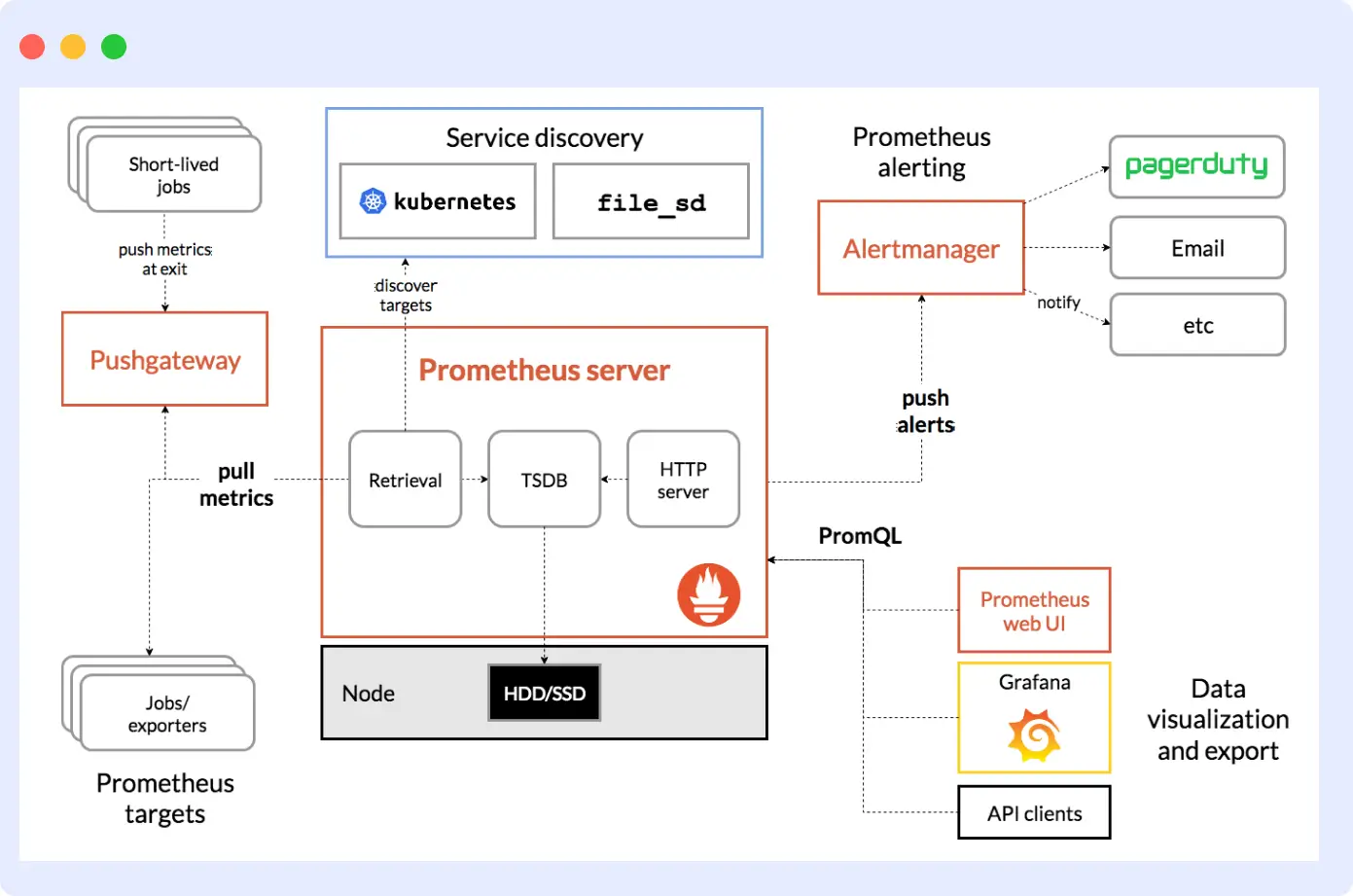
Running it in production does require real investment, though. There is no built-in long-term storage, so most teams add Thanos or VictoriaMetrics to handle retention. Grafana is usually added separately for dashboards and charts. You run all of it yourself, which means keeping it up, scaling it, and maintaining it all falls on your team.
Pros:
- Natively tracks host, container, and Kubernetes resource metrics
- PromQL gives you flexibility for queries and alerts on infrastructure data
- No outside dependencies needed to get started
- Large, active community with plenty of integrations
Cons:
- No built-in long-term storage
- You are responsible for running, scaling, and maintaining it yourself
- PromQL takes time to learn
- Needs Grafana separately for dashboards
Pricing:
- Self-hosted: Free
- AWS Managed Prometheus: ~$0.90/10M samples ingested
- Grafana Cloud: Free for the first 10,000 series; $8/1,000 series after
4. Dynatrace
Dynatrace is built for large organizations running complex infrastructure across multiple clouds, where setting things up host by host just does not work at that scale. Its OneAgent automatically finds every host, container, process, and cloud service in your environment and starts collecting CPU, memory, network, and disk metrics without you having to configure each one manually. It also maps how your infrastructure components connect to each other, so when something goes wrong, you can see at a glance what is affected.
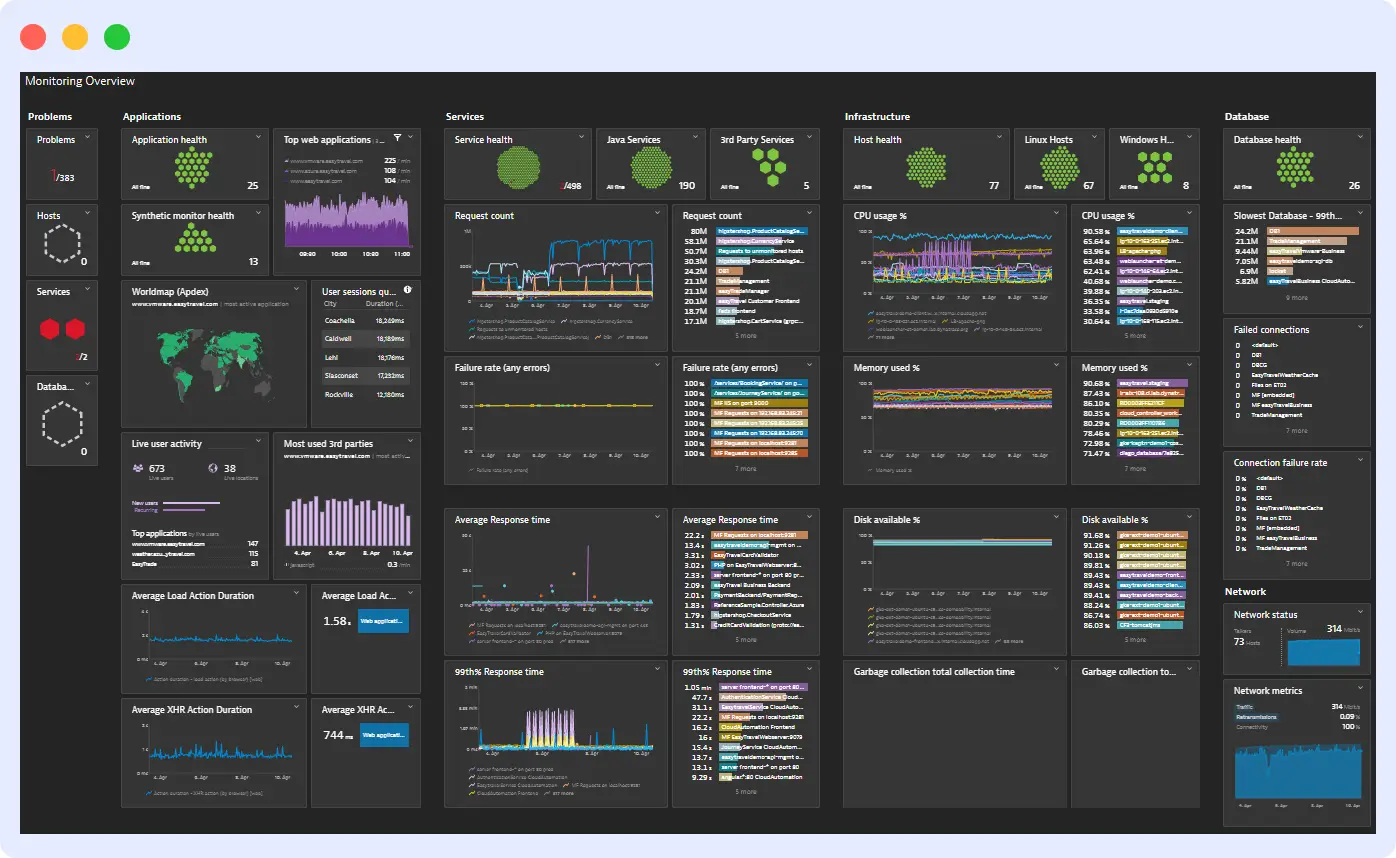
That level of automation is genuinely useful when you are managing hundreds of hosts across different environments. For smaller teams or more straightforward setups, the complexity and cost are hard to justify.
Pros:
- OneAgent automatically discovers and monitors every host and container without manual setup
- Maps dependencies across your full infrastructure automatically
- Strong support for Kubernetes, AWS, Azure, GCP, and OpenShift
- Handles hybrid and multi-cloud environments well
- Alerts on infrastructure problems with context, not just raw numbers
Cons:
- Gets expensive quickly as you add more hosts
- Uses its own query language, which ties you to the platform
- Takes time to get comfortable with, especially when starting out
Pricing:
- Infrastructure Monitoring: $0.04/host/hr (~$29/mo per host)
- Full-Stack Monitoring: $0.08/hr for an 8 GiB host (~$58/mo)
- Kubernetes monitoring: $0.002/hr per pod
5. Zabbix
Zabbix is a well-established open-source monitoring tool built for tracking the health of networks, servers, VMs, containers, and databases. It supports both agent-based and agentless monitoring via protocols such as SNMP, IPMI, and SSH, making it flexible enough to handle mixed environments that some commercial tools handle poorly.
It is free to use, and a basic setup can be running in under ten minutes. The challenge comes when configuring it for larger or more complex environments, which takes time and patience. The documentation is thorough, but there is still a real learning curve.
Pros:
- Tracks servers, VMs, containers, networks, and databases
- Supports agent-based and agentless monitoring across different infrastructure types
- Large library of ready-made templates for common platforms
- Automatically finds devices and hosts on your network
- Runs on-prem, in the cloud, or a mix of both
Cons:
- Initial setup can be complex for people new to it
- Scaling to very large environments needs extra tuning
- Paid support is required for enterprise-level help
Pricing:
- Self-hosted: Free forever
- Zabbix Cloud: From $50/mo (managed version)
- Paid support and consulting are available separately
6. Nagios
Nagios has been around since 1999 and is still widely used in traditional IT environments, particularly for server and network monitoring. It runs on a plugin-based setup where you define exactly what gets monitored and how alerts fire. That flexibility is its biggest strength, with plugins available for almost any piece of infrastructure you need to track.
It comes in two versions: Nagios Core (free, open-source) and Nagios XI (paid, with a more modern interface and extra features). Core is still heavily used in older environments, but everything is configured through files, which feels dated next to newer tools. XI makes that easier, but at a cost.
Pros:
- Very flexible through plugins, as it covers servers, network devices, and virtually any infrastructure component
- Strong alerting with custom notifications and escalation rules
- Proven reliability over many years of real-world use
Cons:
- Core’s file-based setup is time-consuming and not beginner-friendly
- The interface, especially in Core, looks and feels old
- Some features require the paid XI version or significant extra work to set up
Pricing:
- Nagios Core: Free and open-source
- Nagios XI Standard: From $2,495 (one-time license)
- Nagios XI Enterprise: From $4,490 (one-time license)
7. Uptrace
Uptrace is an open-source IT infrastructure monitoring tool built on OpenTelemetry. It collects infrastructure metrics, traces, and logs from your servers, containers, and cloud services and consolidates them into a single place. Because it is built on OpenTelemetry, it integrates with whatever you are already running, without replacing your existing setup.
It is a good fit for teams that want to monitor their infrastructure without being tied to a single vendor. That said, you will need a solid understanding of OpenTelemetry to configure it and get the most out of it, and the ecosystem is smaller than that of commercial tools.
Pros:
- Collects infrastructure metrics, traces, and logs in one place
- Built on OpenTelemetry and also works with your existing instrumentation
- Connects with Prometheus, FluentBit, Vector, CloudWatch, and more
- Pricing is based on data volume, so it stays predictable
Cons:
- Requires a solid understanding of OpenTelemetry to set up properly
- Fewer integrations than more established tools
- Smaller community compared to commercial platforms
Pricing:
- Community Edition: Free (self-hosted)
- Cloud plans: From $30/mo, based on how much data you send in
8. App Dynamic
AppDynamics (now part of Cisco) monitors your servers, containers, cloud environments, and databases and shows you how the health of each affects the rest of your infrastructure. It tracks CPU, memory, and overall resource usage across hosts, and provides a dependency map showing how a struggling server can affect other servers connected to it. Additionally, the platform supports both cloud-hosted and self-hosted deployments, giving larger organizations more flexibility in how they run it.
It is built for large enterprises with complex, multi-layer infrastructure. For smaller teams or simpler environments, the cost and setup time are hard to justify.
Pros:
- Tracks server, container, and cloud resource health in one place
- Dependency mapping shows how infrastructure issues spread across your environment
- Works with both cloud-hosted and self-hosted deployments
- Handles multi-cloud and hybrid infrastructure setups
- Detailed host-level diagnostics for finding resource bottlenecks
Cons:
- Expensive, especially in large environments
- Takes time to learn and get fully set up
- Some monitoring capabilities are priced as separate add-ons
Pricing:
- Infrastructure Monitoring: From $6/vCPU/month
- Advanced plans: From $33/vCPU/mo and $50/vCPU/month
9. Paessler PRTG
PRTG monitors your infrastructure through sensors, and each sensor watches a specific aspect, such as a network interface, a server’s CPU load, a disk’s free space, or bandwidth usage on a switch. This gives you precise control over exactly what gets tracked across your infrastructure and avoids collecting data you do not need.
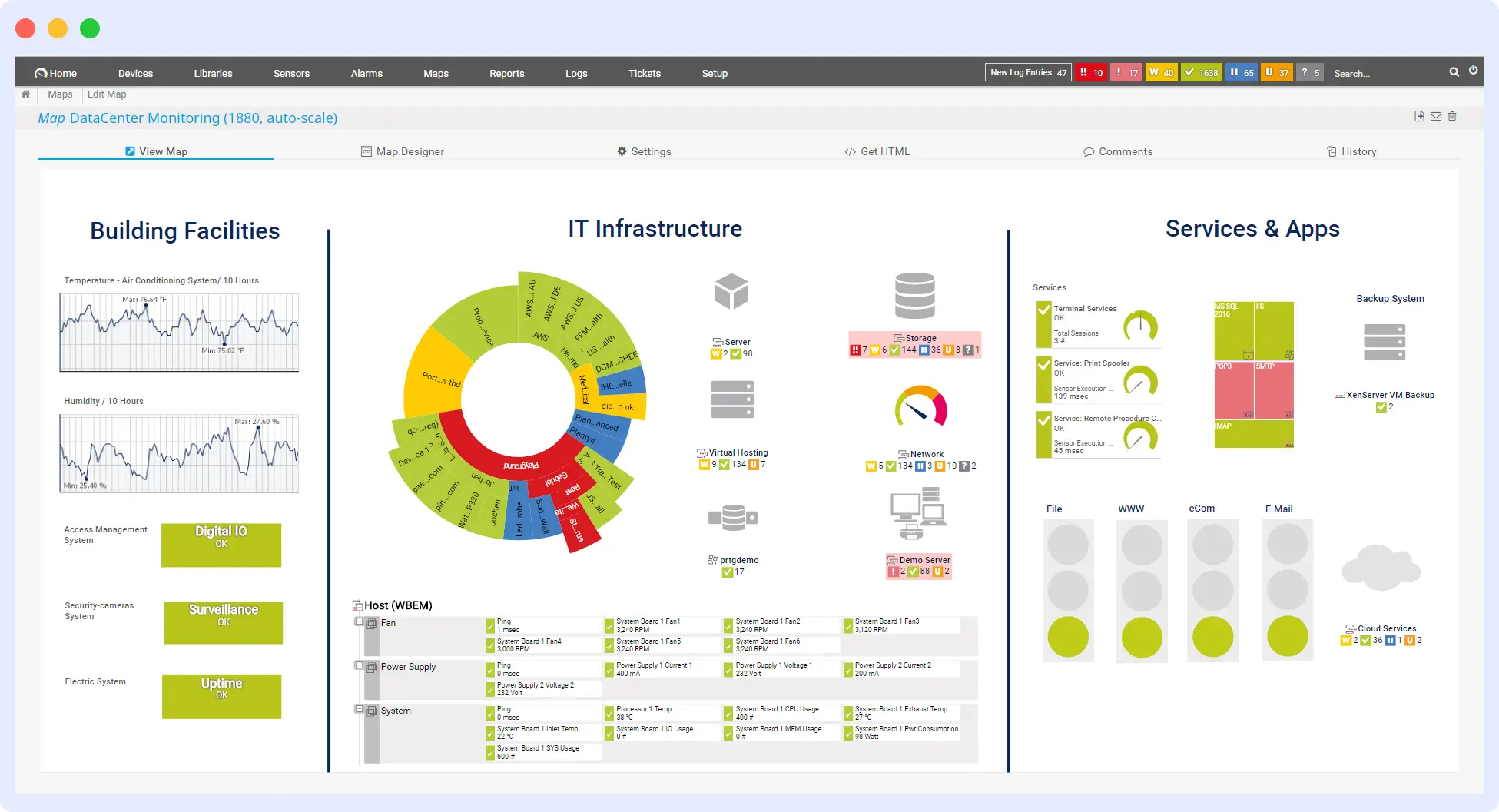
It works particularly well for on-prem environments with networks, servers, and hardware devices. Setup is not complicated, and the built-in map editor lets you build a visual layout of your infrastructure. It gets costly when your infrastructure scales because each monitored component needs its own sensor.
Pros:
- Track exactly what you need. Each sensor monitors one specific infrastructure component
- Good fit for on-prem servers, network devices, and hardware
- Visual map editor for custom infrastructure layouts
- Works with SNMP, WMI, SSH, and other standard protocols
- Real-time alerts via email, SMS, and push notifications
Cons:
- Not well-suited for cloud-native or container-heavy environments
- Costs grow as you add more things to monitor
Pricing:
- Free: Up to 100 sensors
- PRTG 500: From $2,149/yr (500 sensors)
- PRTG 1000: From $3,399/yr (1,000 sensors)
- PRTG Hosted Monitor: From $149/mo
10. Solarwinds AppOptics
SolarWinds AppOptics is a SaaS-based infrastructure monitoring tool that gives you a single dashboard view across all your hosts, containers, and servers. It tracks CPU, memory, disk, and network performance at the host level and uses color-coded heat maps to make it easy to spot which servers are under strain at a glance. Dashboards update in real time as servers and containers are added or removed, so you are always looking at your actual infrastructure rather than a stale snapshot.
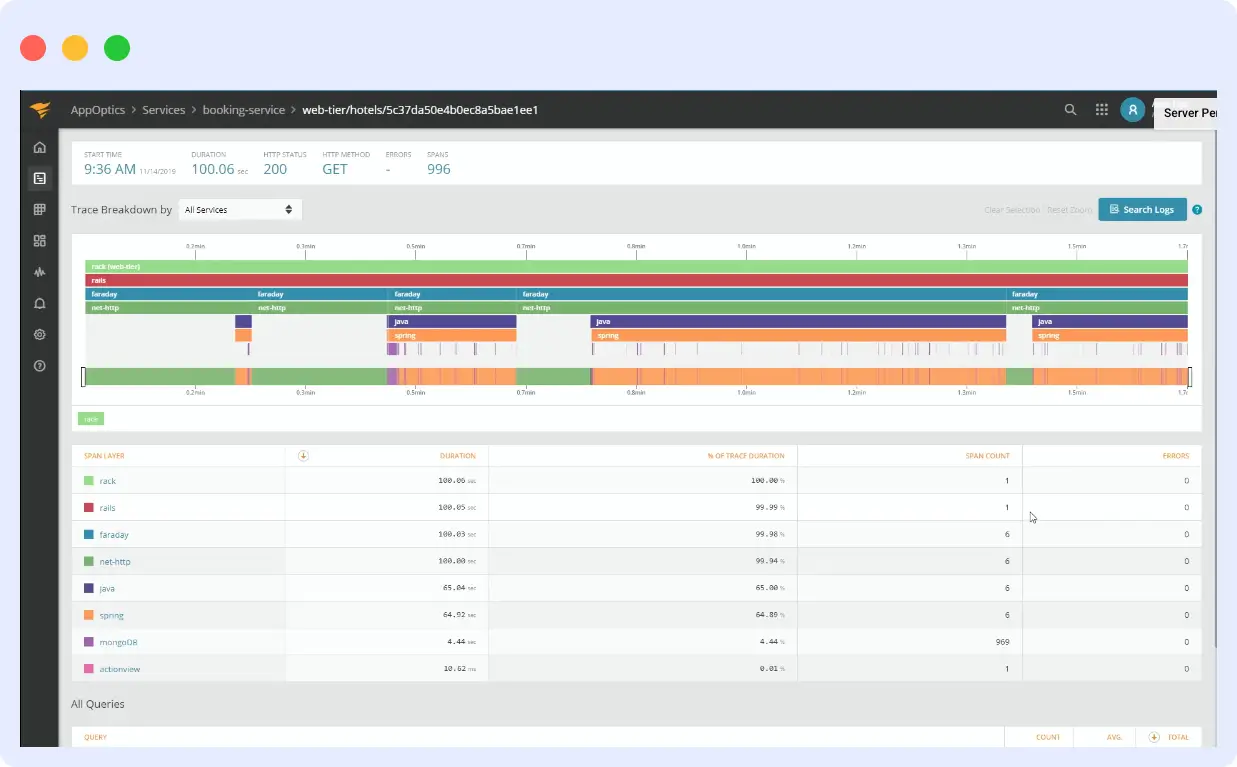
It covers on-prem, cloud-hosted, and hybrid environments and comes with 150+ integrations out of the box. Setup is straightforward, and the alerting system lets you set custom thresholds and get notified before a resource issue escalates.
Pros:
- Real-time host and container monitoring with heat maps for quick visibility
- Dashboards update automatically as your infrastructure changes
- 150+ integrations, including AWS and Azure services
- Works across on-prem, cloud, and hybrid environments
- Simple per-host pricing with no surprise charges
Cons:
- Sold in packs of 10 hosts, so pricing is not as granular for very small setups
- Less suited for very large, complex Kubernetes environments
- Fewer infrastructure-specific features compared to more established enterprise infrastructure monitoring tools
Pricing:
- 30-day free trial available
- Infrastructure Monitoring: $9.99/host/mo (billed annually, sold in packs of 10 hosts)
How to Choose an Infrastructure Monitoring Tool
Before shortlisting any tool, run through these four checks:
- What does your setup look like? Are you running traditional servers on-prem or in the cloud, or containerized workloads? If your workloads are short-lived and containerized, you need a tool built from the ground up for that, not one that adds container support as an afterthought.
- How much data do you actually need? If your setup is straightforward, tracking core metrics such as CPU, memory, disk, and network usage might be enough. But if you are running many servers or Kubernetes clusters and need to understand exactly where a resource problem originates, you will want a tool that provides deeper visibility across your hosts. Trying to piece that together from separate tools later is more work than it is worth.
- How much do you want to manage yourself? Self-hosted tools give you full control, but keeping them running, scaling them, and staying on top of updates are up to you. If your team would rather not deal with that, a managed platform saves time even if the monthly cost looks higher.
- What will it cost as you grow? Pricing that looks reasonable now can get expensive fast once you have more servers, more data, or more team members using the tool. Before you commit, think about where your infrastructure will be in a year and check whether the pricing still makes sense at that size.
Conclusion
Every tool on this list works well for the right team and setup. Open-source options make sense if your team has the time and skills to run them. The larger commercial platforms are a good fit for big organizations that need a wide range of integrations and are willing to pay for them. For most teams, the real question is how much visibility you need versus how much you want to spend and manage.
If you want metrics, logs, and traces in one place without the complexity or the price tag of the bigger platforms, Middleware is worth trying. The free tier covers 100 GB per month, which is enough to test it with your real infrastructure before spending anything. Start for free with Middleware

Leave a Reply