Tag: Observability
-

Platform Engineering Needs Observability: Here’s Why
Discover how observability streamlines platform engineering by solving complexities, optimizing workflows, and ensuring system reliability.
-

What is LLM Observability?
Discover the importance of LLM Observability. Learn how to optimize Large Language Model performance, detect issues, and ensure reliability.
-

Why Real-Time Alerts Matter More Than Ever
Discover how Middleware’s real-time alerting surpasses traditional delayed alerting windows. Learn how instant notifications for critical issues can prevent downtime and enhance uptime reliability.
-
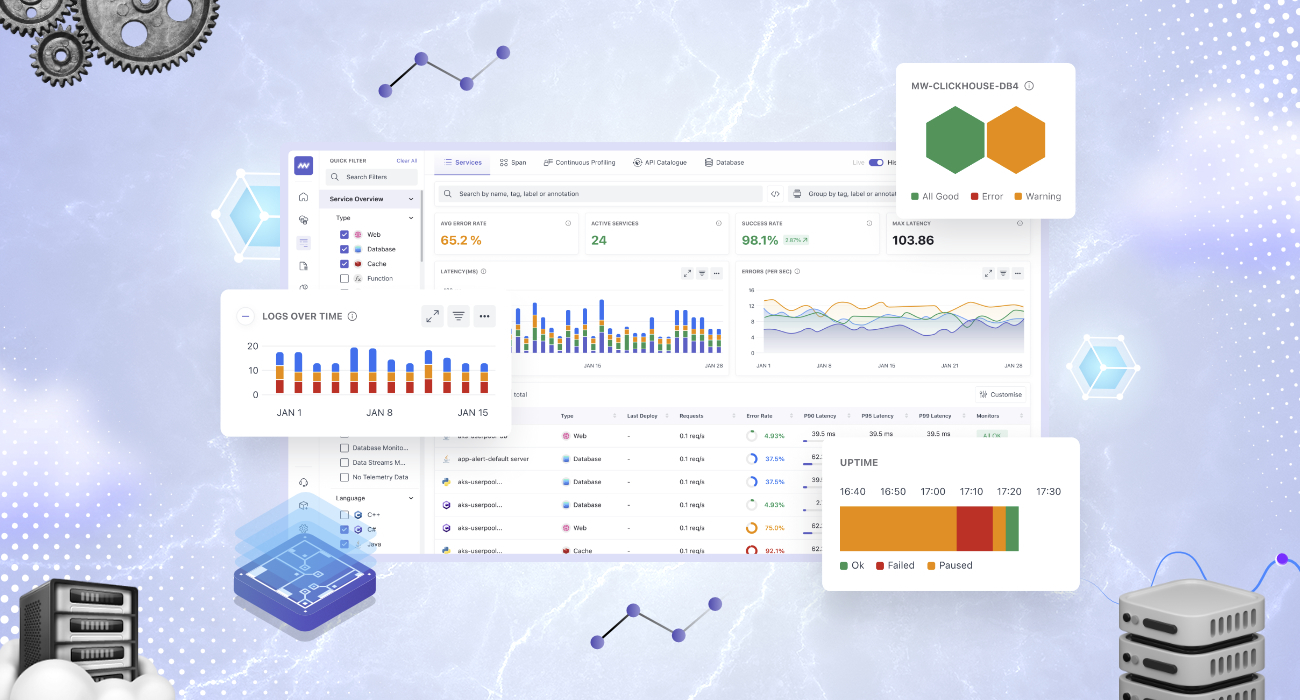
Middleware’s Observability Platform Gets a Big Makeover
Middleware’s new and improved platform provides complete control over telemetry data and costs, new monitoring capabilities, faster root cause analysis, and broader integration support. Over the last few years, we’ve witnessed a fundamental shift, driven by the relentless growth of complex, distributed systems. Monolithic applications are giving way to microservices architectures, and with them, a…
-

Understanding Observability Maturity Model: 3 Things to Know
Discover the essentials of the observability maturity model, including its need, levels, and capabilities. Learn how it helps improve system reliability, performance, and user experience in modern IT environments.
-

Open-source vs. Managed Observability Platforms
Struggling to choose between Open-source and Managed Observability platforms? We’ll break down the pros and cons of each platform, to help you pick the perfect fit for your needs.
-

5 Tips to Reduce Your Observability Costs
Worried about skyrocketing observability costs? We’ve got you covered! Discover 5 practical tips to optimize your observability spending.
-

MTTR vs. MTTD: What’s the difference?
Confused by MTTR and MTTD? Read on to understand it better and how it can help improve your team’s incident response and minimize downtime.
-

Top 10 Observability Tools in 2026
Empower your DevOps teams with the top observability tools in 2024. Dive into our guide to discover top solutions like Middleware, Dynatrace, and others.
-

Top 9 Incident Management KPIs to Keep an Eye On!
There are 30+ incident management KPIs. But not all are important. Here are the top 9 KPIs you should be keeping an eye on!
-

Flame Graphs: What They Are? And How To Use It
A Flame Graph is a visual representation of software stack traces, portraying the execution flow of a program. Know more about it here:
-

What is Alert Fatigue? A DevOps Guide On How to Avoid It
Alert fatigue carries a significant implication in the IT sphere. In fact, 28 % of teams forget to review a critical alert because of it. Learn more about it here: