Tag: Kubernetes
-

Docker Status: How to Check If Docker Is Down and Fix Common Errors
Docker status isn’t one thing. When a container looks off, you’re never sure whether to check the daemon, the container itself, or the app running inside it, and there’s no single docker status command that just tells you. This guide gives you the exact command for each of the three status types, so you can find what’s…
-

AI SRE Agent for On-Call Engineers: How OpsAI Cuts MTTR From Hours to Minutes
On-call engineering is one of the hardest knowledge-transfer problems in software, and most AI SRE agent for on-call engineers conversations start in the wrong place. A junior engineer inherits a production system at 2 AM with a P1 alert firing. They have no context for why the service behaves the way it does. Traditional runbooks…
-

How AI-driven alerts caught a memory leak before it became an outage
A memory leak was growing quietly in production, invisible to threshold-based monitoring. Within hours of deploying the middleware, the team behind it received an AI-driven alert that flagged the anomaly before it could cascade into a full outage. TL;DR A memory leak grew silently in production until an AI-driven alert flagged the anomaly hours before pods would…
-

Kubernetes CrashLoopBackOff: Causes, Diagnosis, and Fixes
Summary: CrashLoopBackOff is one of the most common and most frustrating Kubernetes errors engineers face in production. It means a container keeps crashing and restarting in a loop, but the error actually causing it is hidden inside logs and exit codes that most guides gloss over. This article covers every root cause in depth, gives…
-

What Is Kubernetes ImagePullBackOff Error and How to Fix It
Summary: ImagePullBackOff is a Kubernetes pod status that prevents your application from starting before it can pull the image. The container image can’t be pulled from the registry, so nothing runs. It’s one of the first errors engineers hit when deploying to Kubernetes, and while the fix is almost always straightforward once you know the…
-

AWS ECS vs EKS: What’s the Difference and Which Should You Choose?
Summary: Use AWS ECS if your team wants AWS-native simplicity, lower operational overhead, and no per-cluster fee. Use AWS EKS if you need Kubernetes portability, the CNCF tooling ecosystem (Helm, Argo CD, Istio), or fine-grained autoscaling like KEDA and Karpenter. Both run on EC2 or Fargate, both are production-proven at massive scale, and neither is objectively…
-

Kubernetes Deployment: The Misconfigurations That Cause Outages (and How to Fix Them)
Summary: A Kubernetes Deployment is a declarative API object in the apps/v1 group that manages the full lifecycle of a set of identical Pods, including creation, scaling, rolling updates, self-healing, and rollback. It does not run containers directly; instead, it owns a ReplicaSet, which owns the individual Pods. This three-layer hierarchy — Deployment → ReplicaSet → Pod…
-

OOMKilled Kubernetes Error: How to Detect, Fix, and Prevent It
OOMKilled Kubernetes error is one of the most disruptive errors in containerized production environments. The Linux kernel kills your container mid-flight with no warning, drops all in-flight requests, and forces Kubernetes to restart the workload from scratch. If the root cause is not addressed, the cycle repeats until the pod enters CrashLoopBackOff and your service…
-
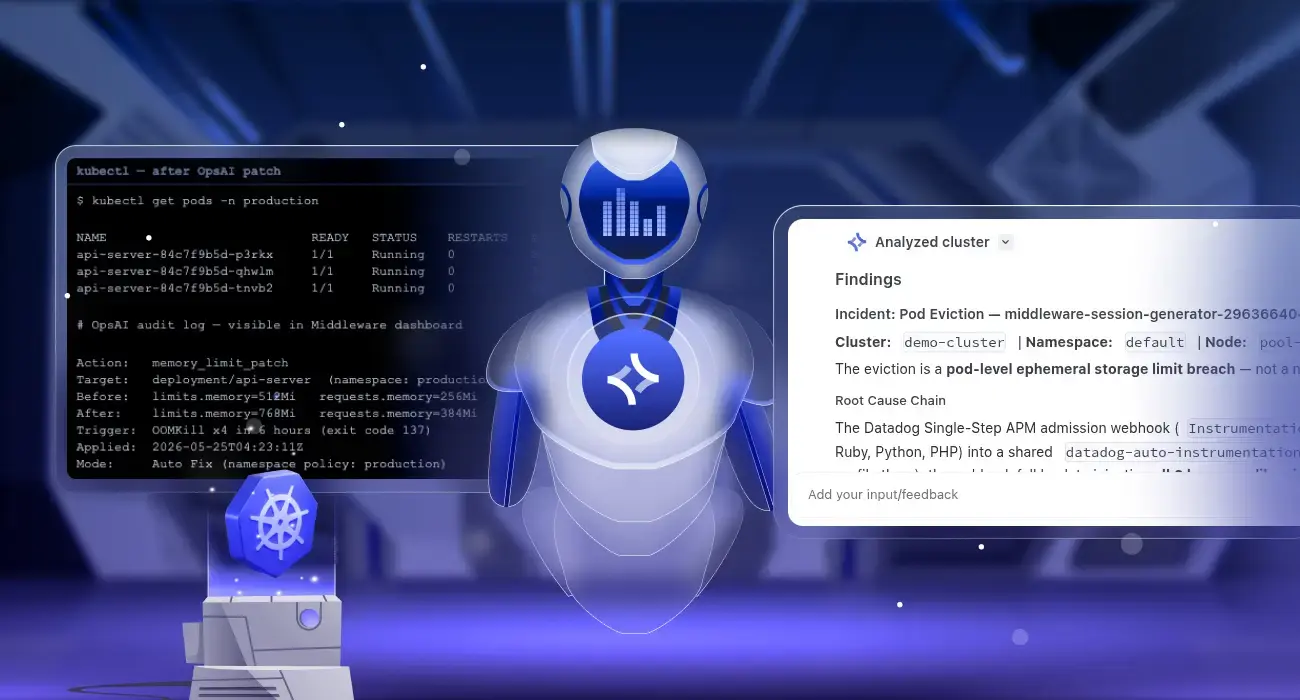
Kubernetes Self-Healing: Automatic Pod Crash Remediation with OpsAI
Kubernetes pod crash auto-remediation is the ability to automatically detect why a pod crashed and apply a permanent fix without human intervention. Middleware OpsAI does this by monitoring Kubernetes events, pod metrics, and container logs in real time, diagnosing the root cause of each failure, and patching the cluster directly, for example, raising a memory…
-

How We Built an AI SRE Agent That Troubleshoots Production Issues Like a Team of Engineers
We built OpsAI because investigating a production incident has become one of the hardest cognitive tasks in software engineering, and the industry’s answer has been to add more dashboards. That’s the wrong answer. As distributed environments grow, the signals get noisier, failures span more systems, and Kubernetes adds layers that nobody fully understands at 3…
-

Kubernetes Infrastructure Monitoring: Complete Guide with Middleware
Kubernetes infrastructure monitoring tracks node CPU, memory, disk, and network health, as well as control plane and pod status, to surface problems before they affect users. Tools like Middleware provide pre-built dashboards and automated alerts that cut setup time from days to minutes. Table of Contents TL;DR Kubernetes infrastructure monitoring continuously tracks node CPU, memory,…
-
Kubernetes & Docker Exit Code 143: Meaning, Causes, and Debugging Guide
When you see exit code 143 and your container stops, the instinct is to assume something broke. In most cases, the container received a shutdown signal and exited on its own. What matters is whether your application handled that signal correctly. In production, how your application handles that shutdown determines whether users see dropped requests,…